More than 3.2M active Tiger Data databases power apps across IoT, crypto, dev tools, and finance—all built on PostgreSQL. We use PostgreSQL for everything; we built our cloud so you can too.
Supercharged PostgreSQL
TigerData vs vanilla PostgreSQL
Powerful enough for real-time time-series, events, & analytics data
Relational
For traditional database workloads, TigerData provides dynamically scalable compute and more memory even at the base. Plus you only pay for what you store.
Time series & analytics
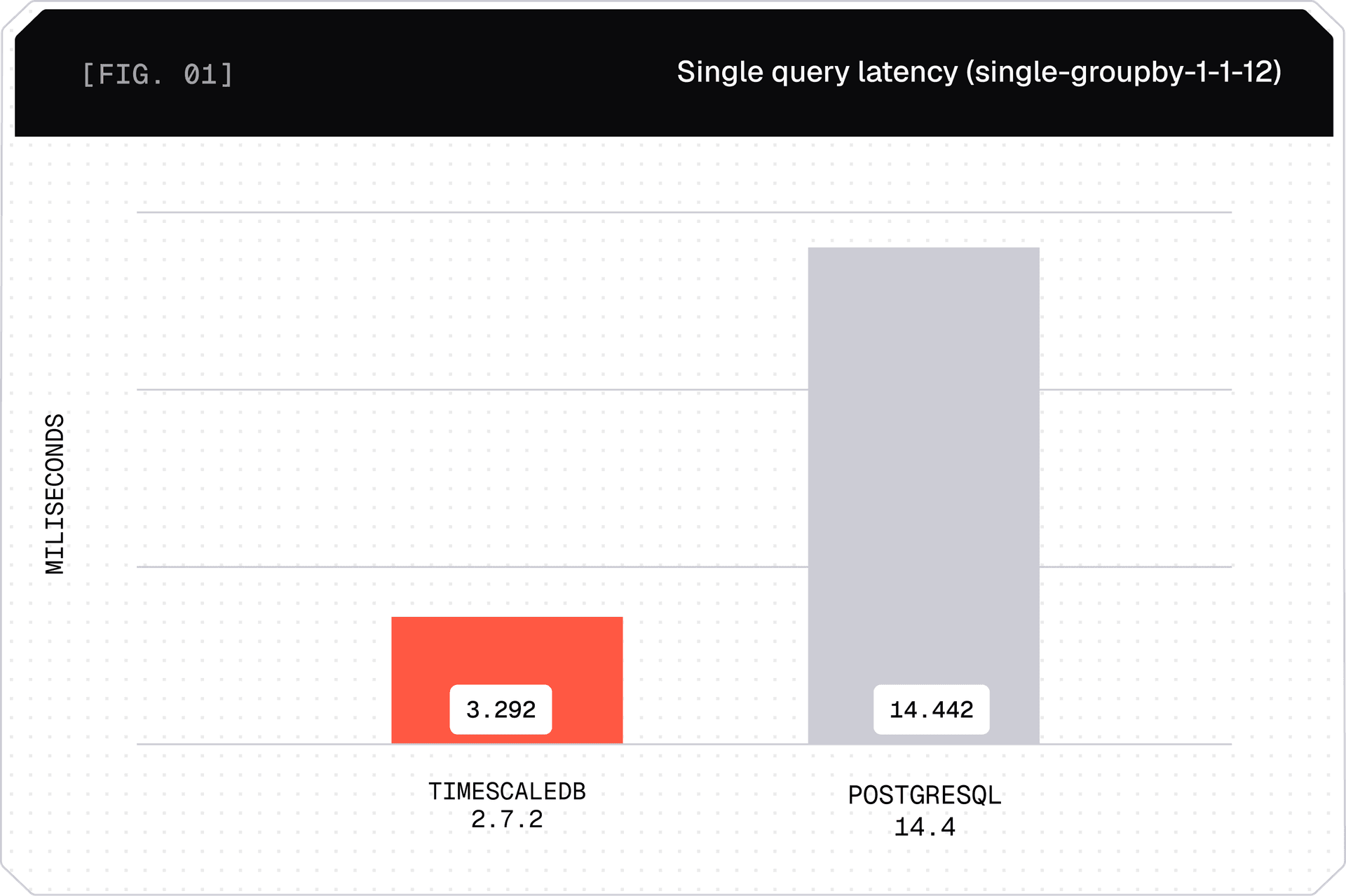
For time series and other demanding workloads that ingest and query high volumes of data, TigerData queries up to 350x faster, ingests 44% faster, and saves 95% storage over RDS.
Vector/AI
For production AI applications that need fast search with high recall on millions of vector embeddings, TigerData offers a vector engine.
High-performance data analysis
Infinitely scalable
Cost-effective and flexibly priced
Postgres-compatible
Use the PostgreSQL ecosystem you already know, with familiar extensions, tools, and connectors.
Built-in recovery
Use the PostgreSQL ecosystem you already know, with familiar extensions, tools, and connectors.
Zero-downtime upgrades
Upgrade with confidence, without planning around disruptive maintenance windows.
Storage that scales
Avoid running out of space or managing disk allocations as your data grows.
Right-sized compute
Skip CPU and memory guesswork with infrastructure that adapts to your workload.
Expert support included
Get consultative support to unblock issues without surprise add-on costs.
Postgres-compatible
Use the PostgreSQL ecosystem you already know, with familiar extensions, tools, and connectors.
Built-in recovery
Use the PostgreSQL ecosystem you already know, with familiar extensions, tools, and connectors.
Zero-downtime upgrades
Upgrade with confidence, without planning around disruptive maintenance windows.
Storage that scales
Avoid running out of space or managing disk allocations as your data grows.
Right-sized compute
Skip CPU and memory guesswork with infrastructure that adapts to your workload.
Expert support included
Get consultative support to unblock issues without surprise add-on costs.
The best feature of TimescaleDB: it's all PostgreSQL, always has been. All your tools, all the existing libraries, and your code already work with it. I’m using TimescaleDB because it’s the same as PostgreSQL but magically faster.
Florian HerrengtCo-founder, Nocodelytics
Tiger Data makes Postgres powerful with fast and affordable database features and worry-free cloud services.
Managed Service for TimescaleDB (MST) by AivenSign up | ||
|---|---|---|
Best-in-class PostgreSQL performance | ||
Automatic partitioning via hypertables for efficient indexes and faster ingest | ||
Automatic materialized data aggregations for real-time dashboards and APIs | ||
Faster analytical queries through time/partition-oriented constraint exclusion | ||
Faster limit and distinct queries via ordered appends, skip scans, and other custom planner optimizations | ||
Accelerated scans via segmented columnar storage | ||
Vectorized query execution via SIMD for faster queries | ||
Specialized vector indexes for AI applications | ||
Flexible analysis with Full SQL | ||
Full ecosystem of PostgreSQL features, connectors, and drivers | ||
JOIN time-series and event tables with relational tables | ||
Rich timestamp and timezone support | ||
Flexible time bucketing for time-oriented analysis | ||
Hyperfunctions, including advanced interpolation, approximation, and visualization functions | ||
Geospatial and vector data types | ||
Automated data management policies | ||
Columnar storage format with fast scans | ||
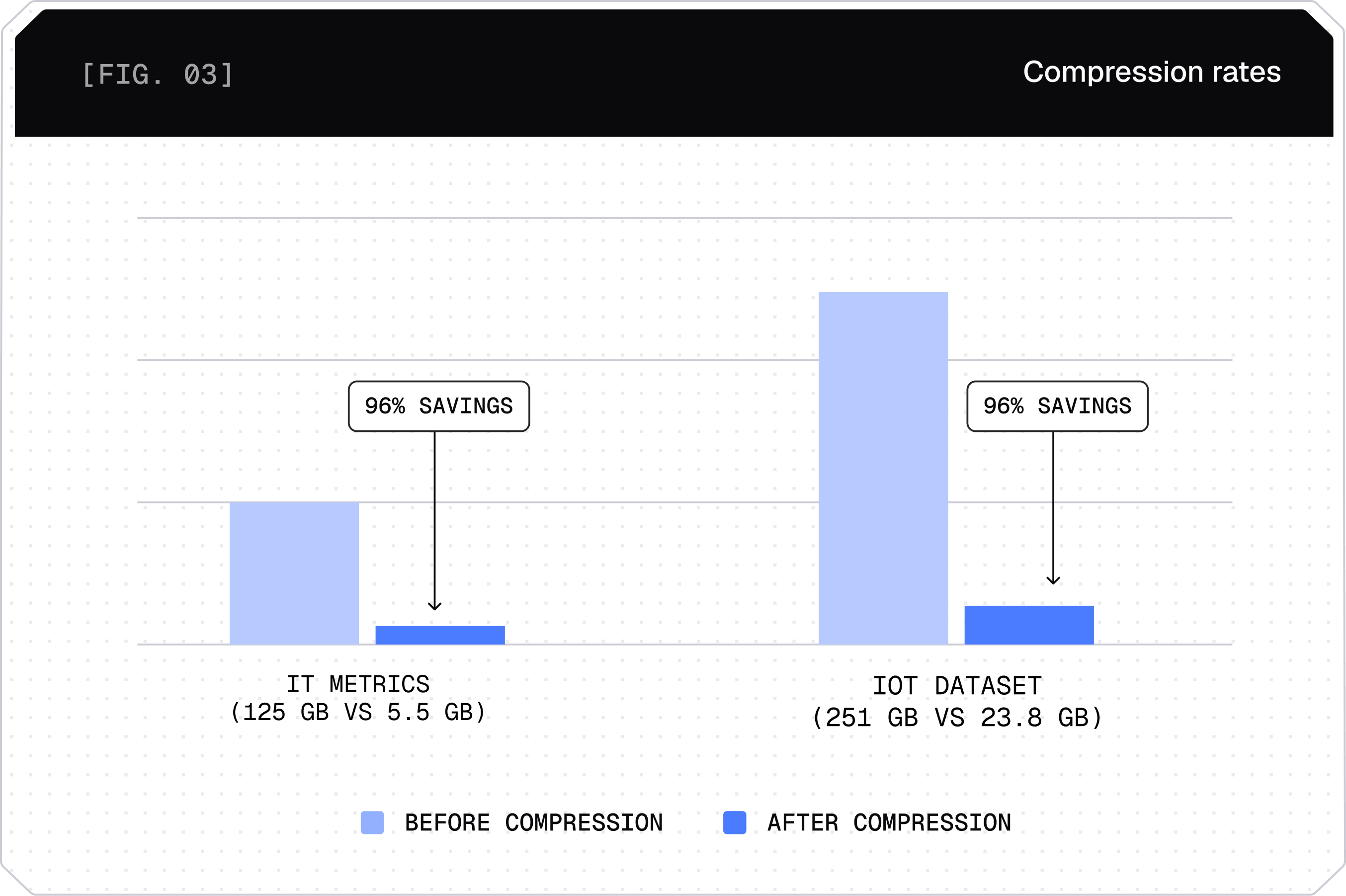
Native compression with 90%+ storage savings | ||
Data retention policies | ||
Data tiering policies | ||
Data reordering for efficient disk scans | ||
Data downsampling for efficient historical analysis | ||
Background job scheduler and user-defined actions | ||
Scalability made easy | ||
Disaggregated compute & storage | ||
Capacity for 100s TB of uncompressed data | ||
Dynamic compute resizing | ||
Dynamic disk storage with usage-based pricing | ||
Dynamic I/O provisioning for high read / write performance | ||
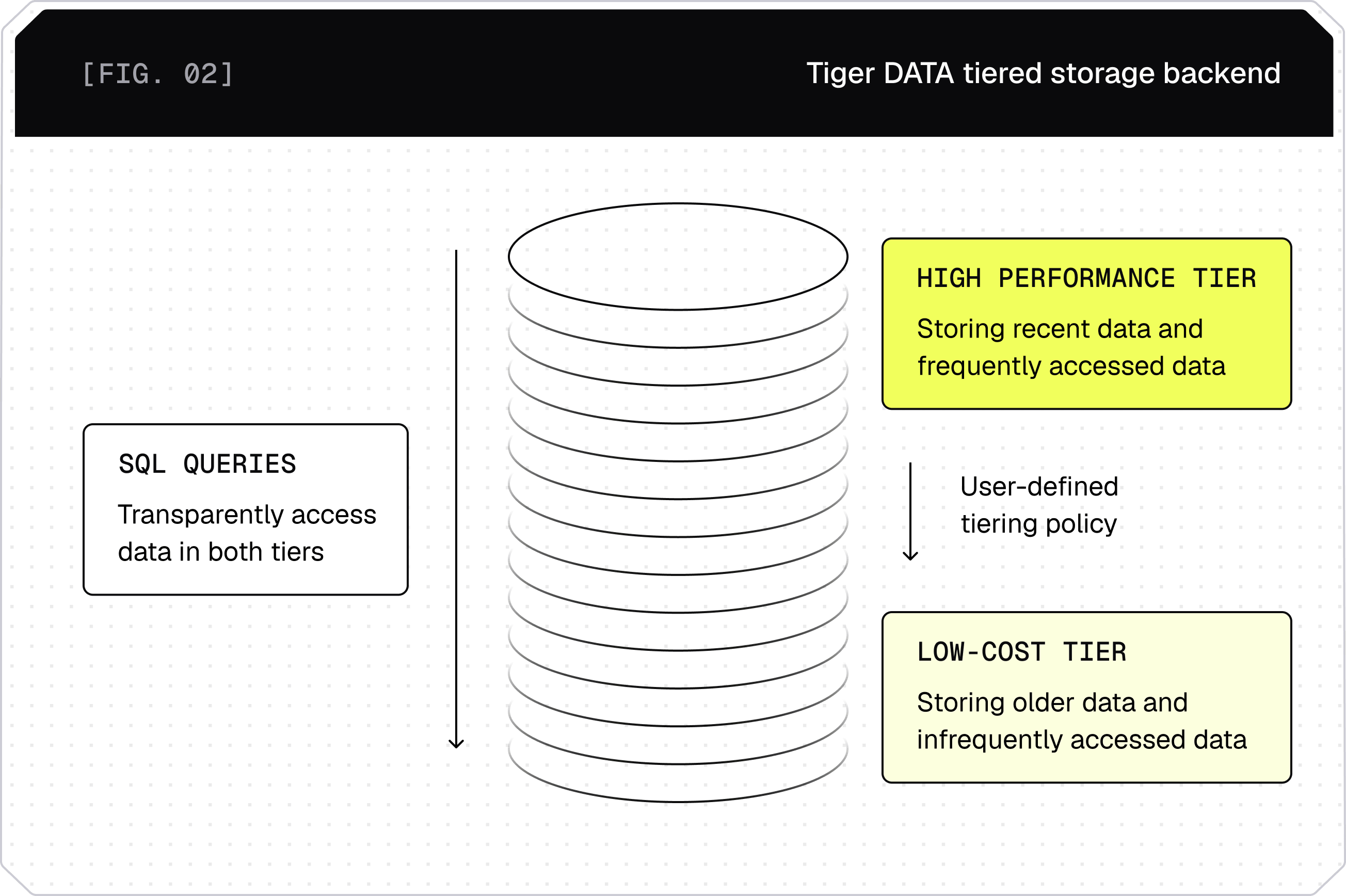
Tiered storage with low-cost infinite storage | ||
Transparent queries across high-performance and low-cost tiers | ||
Read replicas for read scaling | ||
Connection pooling for connection scaling | ||
Automated resource-aware parameter tuning | ||
Terraform for infrastructure-as-code control | ||
High availability and reliability | ||
Multi-AZ (availability zone) deployments for high availability | ||
Continuous incremental backup and automated restore | ||
Point-in-time recovery and branching | ||
Regular database and disk snapshots to enable fast restore | ||
Rapid recovery for all services by fast database restart and remote disk remount | ||
Unique memory guard protections to avoid database out-of-memory crashes | ||
Decoupled control and data planes for greater resilience | ||
Commercial service level agreements (SLAs) | ||
Automated upgrades and software patching | ||
Automated upgrades during configurable maintenance windows to reduce the risk of security vulnerabilities and ensure up-to-date database services | ||
Zero-downtime TimescaleDB and PostgreSQL minor upgrades | ||
PostgreSQL major version upgrades use a forking workflow and disk snapshots to minimize downtime and risk | ||
HA-replica-aware coordinated upgrades | ||
Fleet-wide version and stability monitoring with staged roll-out/roll-back upgrades | ||
Robust security and compliance | ||
SOC 2 Type 2 and GDPR compliance | ||
Data encrypted at rest (both disk and backup) | ||
Data encrypted in transit | ||
Database SSL with fully verifiable certificate chains | ||
Database role-based access control | ||
Multi-factor authentication | ||
Corporate SSO and SAML support | ||
Secure networking including VPC Peering | ||
Layered database "privilege escalation" protections | ||
Secure SDLC practices, automated vulnerability scanning and code analysis, and third-party pen testing | ||
Deep observability | ||
Operational visibility into your databases to understand performance, uncover regressions, and optimize performance | ||
Insights for automated query summaries and statistics | ||
Per-query drill downs into execution times, row results, plans, memory buffer management, and cache performance | ||
In-console metric visualization and system logs | ||
Native metrics and log exporters to AWS Cloudwatch and DataDog | ||
Top-notch support and operations | ||
Follow-the-sun 24x7 support model staffed across APAC, EMEA, and NASA | ||
Production support with Severity 1 responsiveness | ||
Architectural reviews, data modeling and query optimization assistance, feature testing, and migration support | ||
On-call 24x7 operational monitoring and control | ||
Customer Satisfaction (CSAT) scores regularly above 98% | ||
Automatic partitioning via hypertables for efficient indexes and faster ingest
Automatic materialized data aggregations for real-time dashboards and APIs
Faster analytical queries through time/partition-oriented constraint exclusion
Faster limit and distinct queries via ordered appends, skip scans, and other custom planner optimizations
Accelerated scans via segmented columnar storage
Vectorized query execution via SIMD for faster queries
Specialized vector indexes for AI applications
Full ecosystem of PostgreSQL features, connectors, and drivers
JOIN time-series and event tables with relational tables
Rich timestamp and timezone support
Flexible time bucketing for time-oriented analysis
Hyperfunctions, including advanced interpolation, approximation, and visualization functions
Geospatial and vector data types
Columnar storage format with fast scans
Native compression with 90%+ storage savings
Data retention policies
Data tiering policies
Data reordering for efficient disk scans
Data downsampling for efficient historical analysis
Background job scheduler and user-defined actions
Disaggregated compute & storage
Capacity for 100s TB of uncompressed data
Dynamic compute resizing
Dynamic disk storage with usage-based pricing
Dynamic I/O provisioning for high read / write performance
Tiered storage with low-cost infinite storage
Transparent queries across high-performance and low-cost tiers
Read replicas for read scaling
Connection pooling for connection scaling
Automated resource-aware parameter tuning
Terraform for infrastructure-as-code control
Multi-AZ (availability zone) deployments for high availability
Continuous incremental backup and automated restore
Point-in-time recovery and branching
Regular database and disk snapshots to enable fast restore
Rapid recovery for all services by fast database restart and remote disk remount
Unique memory guard protections to avoid database out-of-memory crashes
Decoupled control and data planes for greater resilience
Commercial service level agreements (SLAs)
Automated upgrades during configurable maintenance windows to reduce the risk of security vulnerabilities and ensure up-to-date database services
Zero-downtime TimescaleDB and PostgreSQL minor upgrades
PostgreSQL major version upgrades use a forking workflow and disk snapshots to minimize downtime and risk
HA-replica-aware coordinated upgrades
Fleet-wide version and stability monitoring with staged roll-out/roll-back upgrades
SOC 2 Type 2 and GDPR compliance
Data encrypted at rest (both disk and backup)
Data encrypted in transit
Database SSL with fully verifiable certificate chains
Database role-based access control
Multi-factor authentication
Corporate SSO and SAML support
Secure networking including VPC Peering
Layered database "privilege escalation" protections
Secure SDLC practices, automated vulnerability scanning and code analysis, and third-party pen testing
Operational visibility into your databases to understand performance, uncover regressions, and optimize performance
Insights for automated query summaries and statistics
Per-query drill downs into execution times, row results, plans, memory buffer management, and cache performance
In-console metric visualization and system logs
Native metrics and log exporters to AWS Cloudwatch and DataDog
Follow-the-sun 24x7 support model staffed across APAC, EMEA, and NASA
Production support with Severity 1 responsiveness
Architectural reviews, data modeling and query optimization assistance, feature testing, and migration support
On-call 24x7 operational monitoring and control
Customer Satisfaction (CSAT) scores regularly above 98%
Get started in seconds