Run real-time queries and updates with a row-columnar engine built for speed.
The proof is in production.
This is real-life scale on a single Tiger Cloud service.
250T+
data points stored
1T+
metrics ingested daily
1PB+
of data volume
Co-founder at Nocodelytics
Specialized databases might give you speed and scale — but they struggle with joins, mutability, and ACID guarantees.
Tiger Data gives you it all: blazing fast real-time analytics, high scale, and full SQL — built on PostgreSQL and ready to power your applications.
That’s why we created RTAbench: a benchmark for real-time analytics as it happens in real apps — not just simplified, denormalized workloads.
Explore RTABench
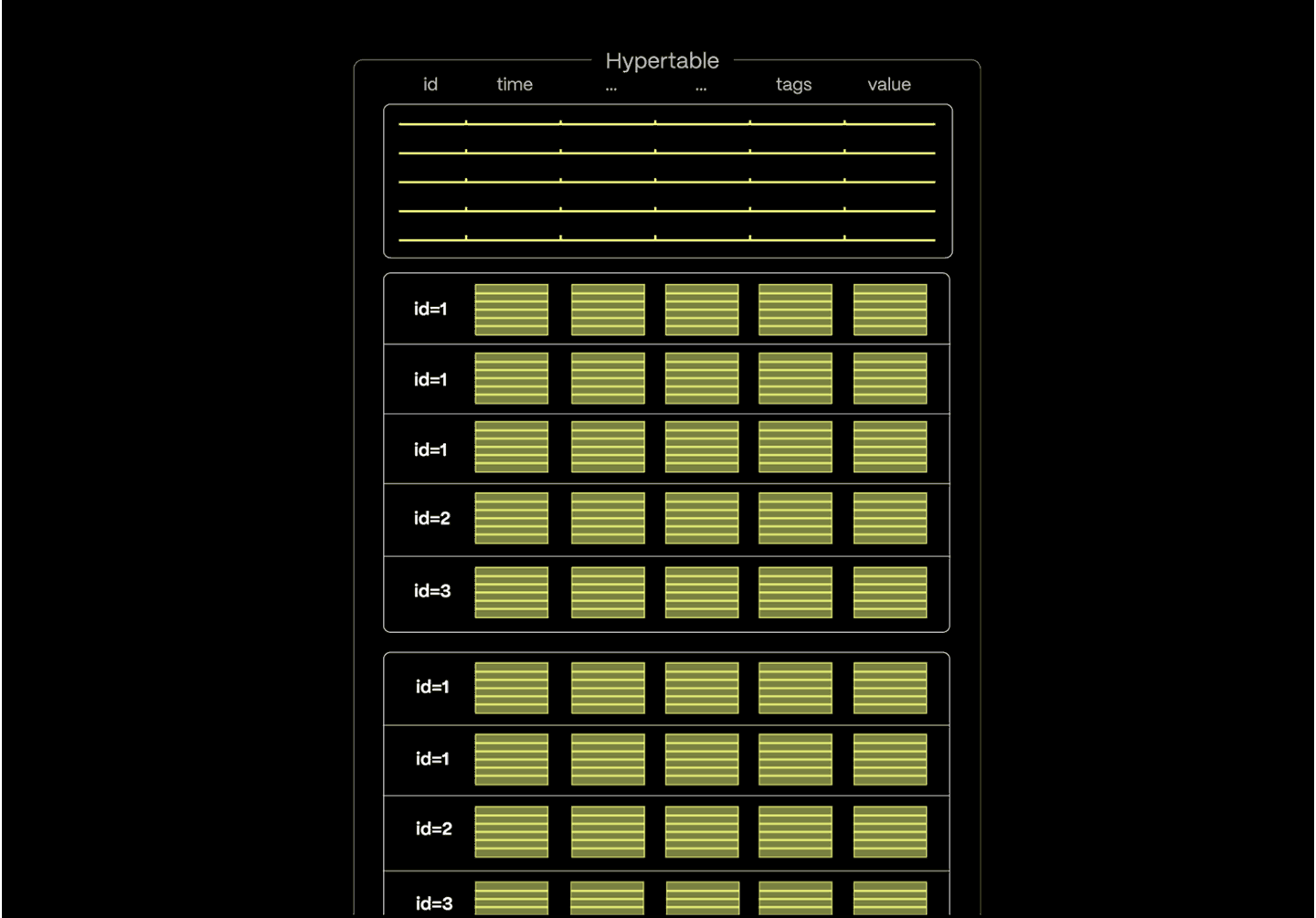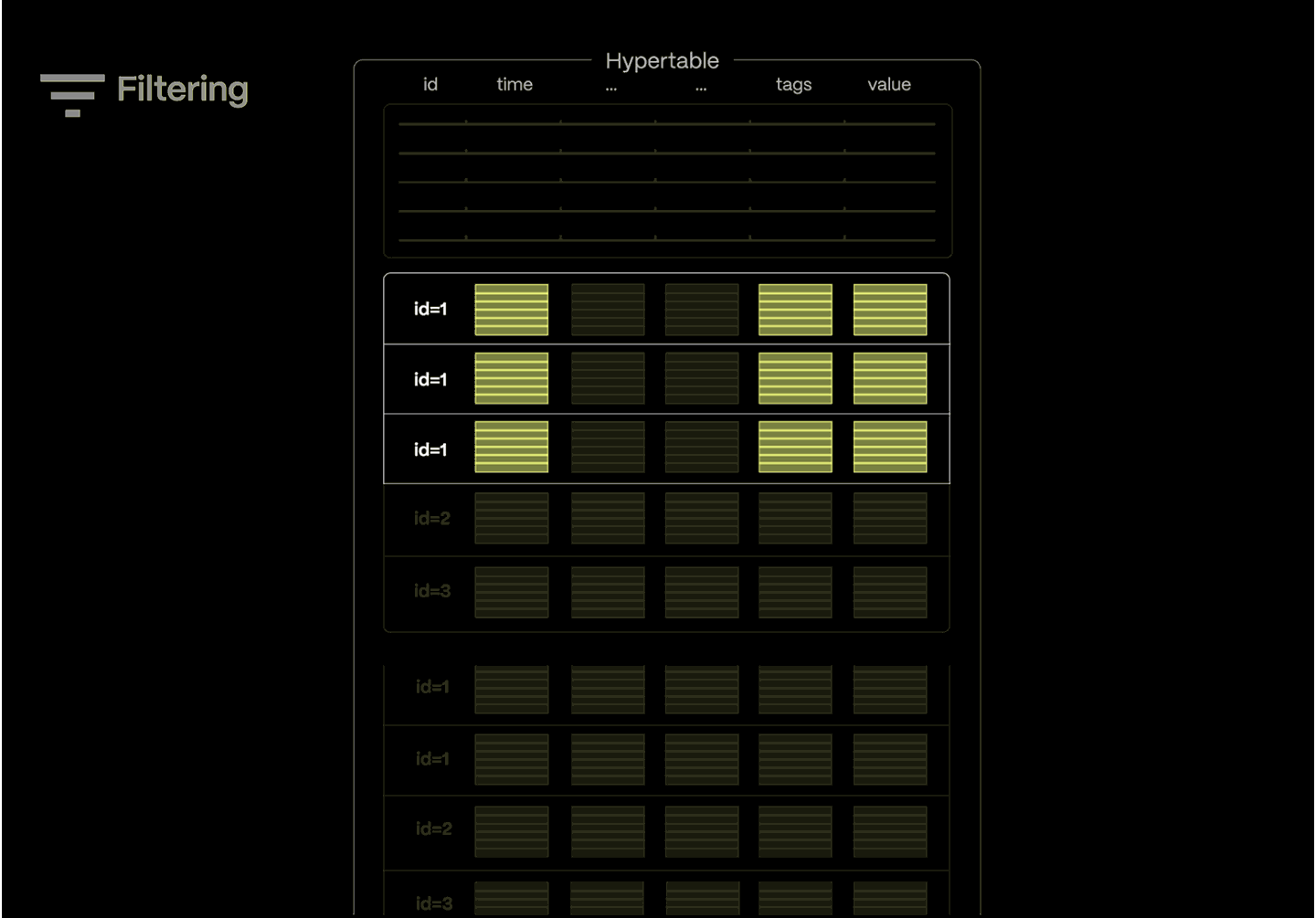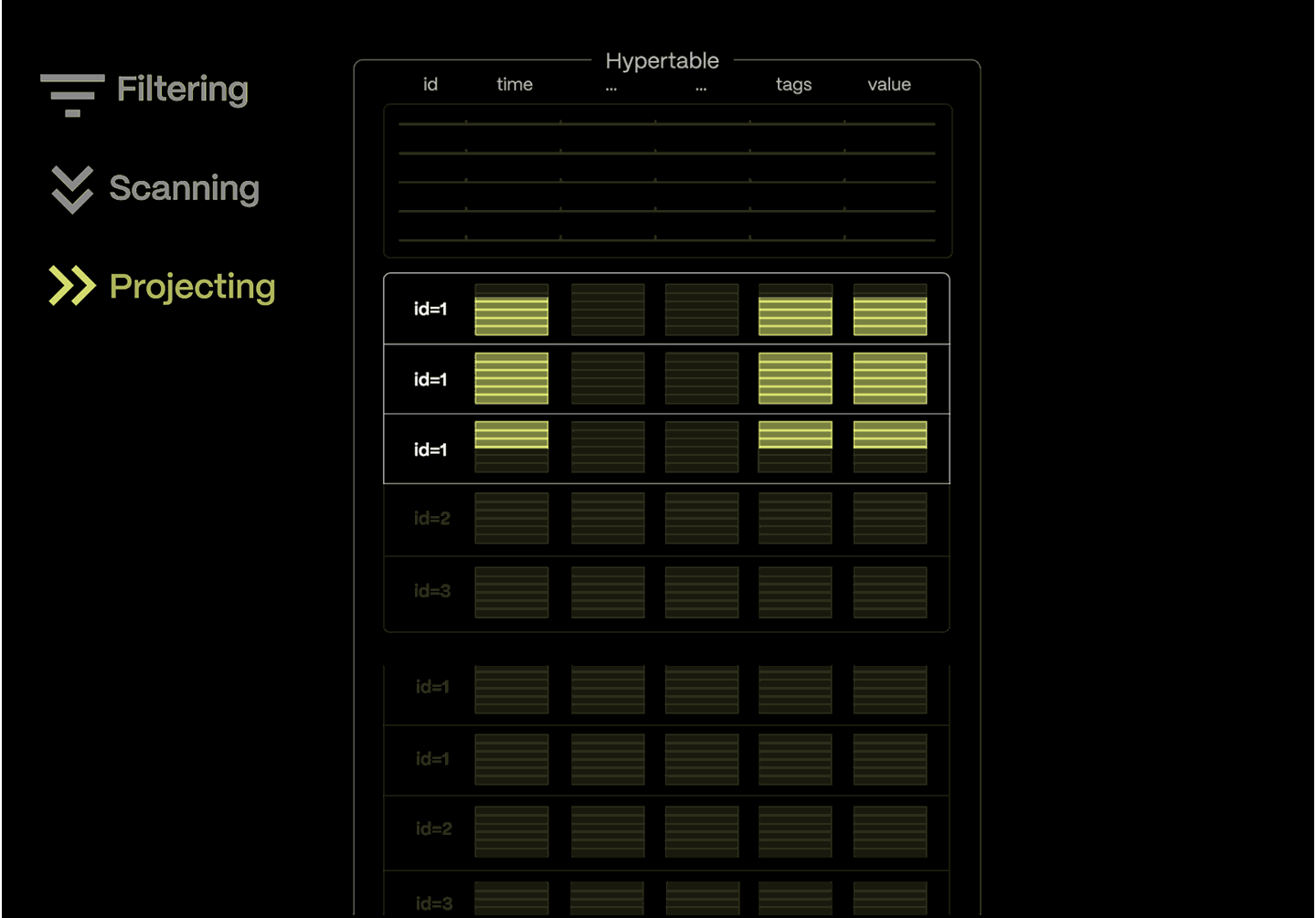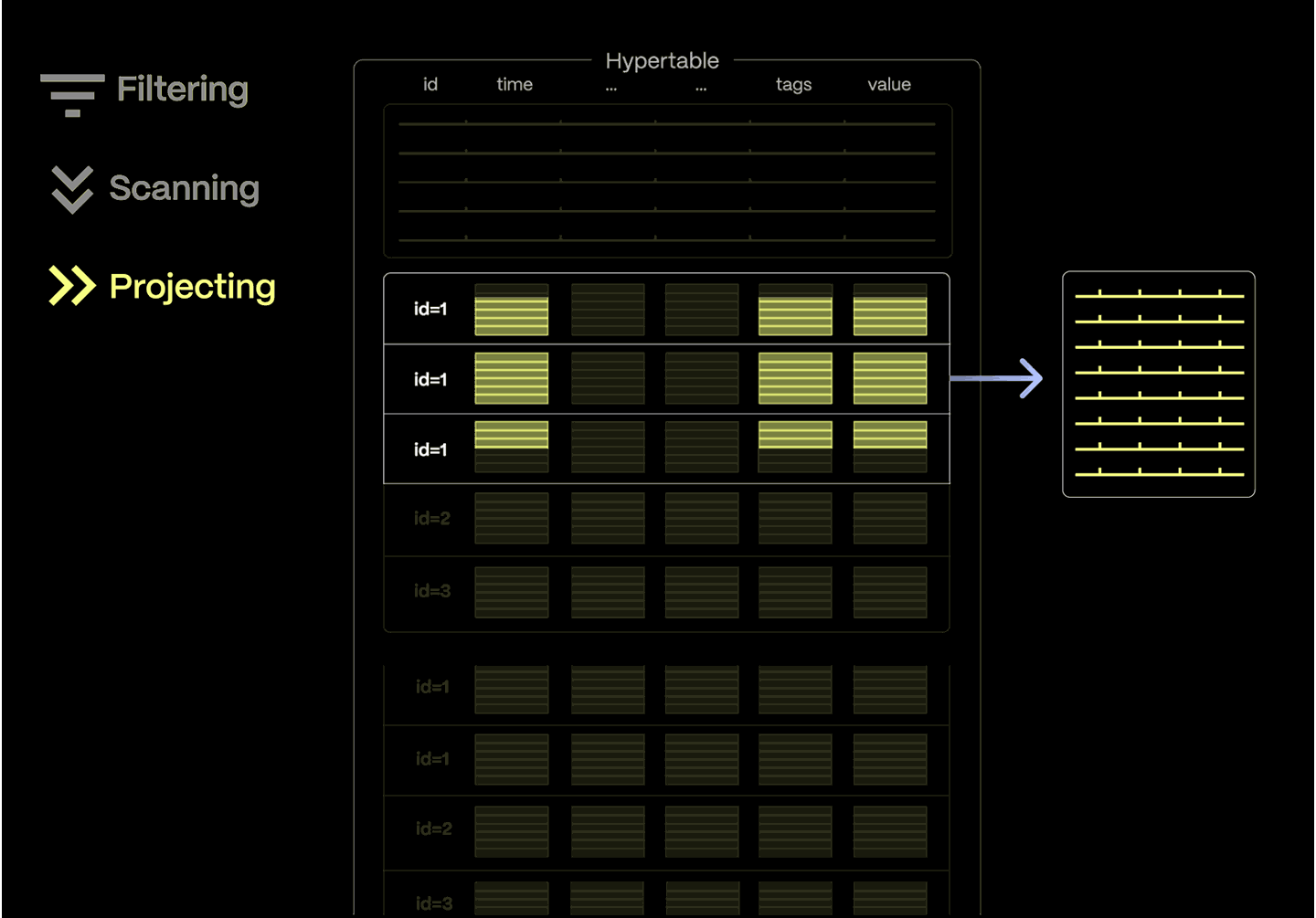
Tiger Data filters out irrelevant data before the query even begins—eliminating time-based partitions and using metadata to skip over large blocks of data.
The rowstore handles high-ingest and point queries with speed, while the columnstore powers fast, parallel scans over compressed columnar data.
With vectorized execution and SIMD acceleration, even complex queries return in an instant.